Building AI-Ready Camunda 8.7 Applications: How Definition Files Turn Vibe Coding into Production-Ready Automation
A practical guide to designing definition files, testing AI-generated code, and scaling reliable vibe coding in Camunda
What is a Definition File in Camunda 8.7?
In Part 1, we explored why AI-generated code fails when it lacks architectural context. This section explains how to solve that problem using definition files — a machine-readable contract between your BPMN model, engineering standards, and AI coding agents. Here’s what one looks like in practice, drawn from a real healthcare pre-authorization workflow:
⦁ Process Identity and Platform
This tells the AI agent which API surface it’s working against. No more generating Camunda 7 embedded engine code when you’re on Camunda 8 SaaS.
Custom Zeebe Worker Definitions
This is the most critical section. Every worker type string must match the BPMN exactly. When an AI agent scaffolds a new @JobWorker method, it pulls the type from this list — not from its imagination.
⦁ Managed Connectors (Hands-Off Zone)
This boundary definition tells the AI agent: “Don’t generate Java code for these. They’re configured in the BPMN modeler and executed by Camunda’s runtime.” Without this, AI agents routinely generate redundant REST client code for things already handled by out-of-the-box connectors.
⦁ Process Variable Schema
Variables are the bloodstream of a Camunda process. Defining their exact names, types, and valid values prevents the single most common hallucination: inventing variable names that don’t match BPMN gateway conditions.
Flow Patterns and Architecture Rules
## Architecture Rules
– Zeebe messages require `.timeToLive(Duration.ofSeconds(60))` or they expire instantly
– Operate API has a 2-5s indexing delay after process publish — poll with retries
– IDP extraction runs 3 parallel branches (DiagnosticReport, InsuranceCard, MedicalForm)
merged at a parallel gateway before validation
– AI Agent connector uses OpenAI gpt-4.1 with structured JSON response format
– All @JobWorker methods must handle `validationError` flag propagation
These are the “gotchas” — tribal knowledge that experienced Camunda developers carry in their heads. Encoding them means an AI agent won’t generate a message publish call without a TTL, or skip retry logic on the Operate API.
Definitions vs. Hallucinations: A Real Comparison
Consider what happens when you ask an AI agent to “implement the claim validation service task” without a definition file:
// AI-hallucinated output (wrong)
@JobWorker(type = “validateClaim”)
public void handleValidation(JobClient client, ActivatedJob job) {
String claimId = (String) job.getVariablesAsMap().get(“claimId”);
boolean isValid = claimService.validate(claimId);
client.newCompleteCommand(job.getKey())
.variables(Map.of(“claimValid”, isValid))
.send().join();
}
Three critical failures: The worker type is wrong (validateClaim’ vs ‘validate-and-save-claim-wrk’). The variable name is wrong (claimValid’ vs ‘claimValidationStatus’). The output value is wrong (boolean’ vs “SUCCESS”/”FAILED” string). This code compiles, passes unit tests, and breaks your process at runtime.
Now with the definition file as a skill:
// Definition-driven output (correct)
@JobWorker(type = “validate-and-save-claim-wrk”)
public void validateAndSaveClaim(JobClient client, ActivatedJob job) {
Map<String, Object> variables = job.getVariablesAsMap();
String mergedJson = (String) variables.get(“mergedExtractionOutput”);
ClaimValidationResult result = claimService.validateAndSave(mergedJson);
Map<String, Object> output = new HashMap<>();
output.put(“claimValidationStatus”, result.isSuccess() ? “SUCCESS” : “FAILED”);
output.put(“validationError”, !result.isSuccess());
output.put(“BusinessKey”, result.getBusinessKey());
client.newCompleteCommand(job.getKey())
.variables(output)
.send().join();
}
Every identifier matches the BPMN. The downstream gateway condition on ‘claimValidationStatus’ evaluates correctly. The ‘validationError’ flag propagates as expected.
Real-World Development Data: Healthcare Pre-Authorization Workflow
To make this concrete, here’s a snapshot from actual development of a healthcare pre-authorization system on Camunda 8.7 SaaS — the kind of complex, multi-path process where vibe coding either shines or catastrophically fails.
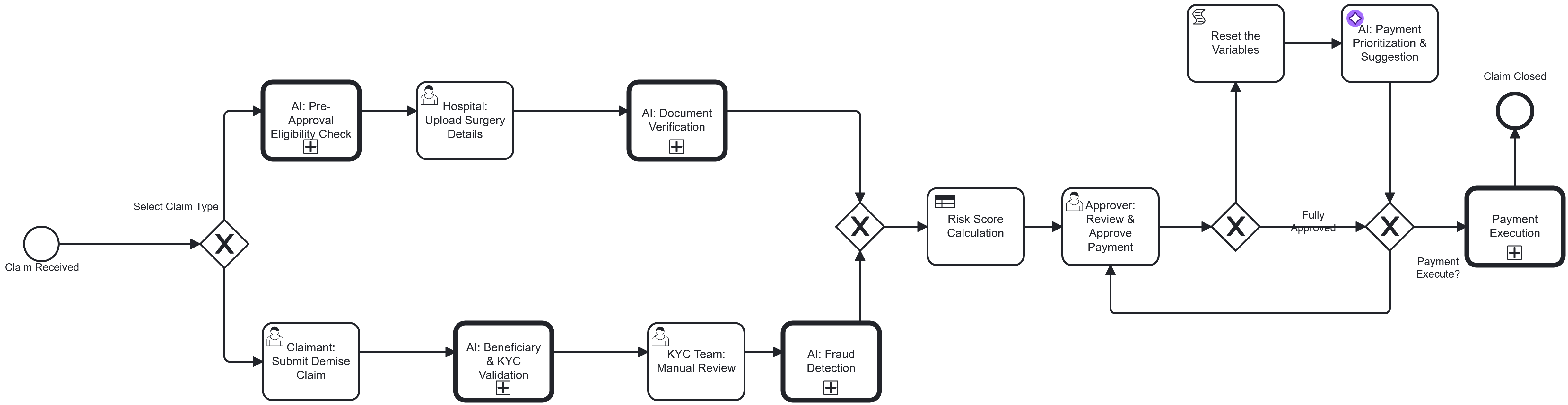
⦁ The Process Complexity
- 2 major paths: Chatbot-driven and Manual document upload
- 7 custom Zeebe workers (uploadDocumentsVerify, validate-upload-documents, merge-output-results-wrk, validate-and-save-claim-wrk, fetch-policy-info-wrk, TestRunSKK, Pre-approval-CaseDetails-sk)
- 3 SaaS-managed connectors (IDP extraction on Gemini 2.5, AI Agent on OpenAI gpt-4.1, HTTP JSON)
- 3 parallel IDP extraction branches (DiagnosticReport, InsuranceCard, MedicalForm)
- 4 human task roles in the approval chain (Customer, Assessor, Manager, Finance)
- 12+ key BPMN variables controlling routing, state, and validation
- Entity relationships spanning Policy → PolicyProduct → PolicyProductICDCoverage → ICD10RuleMaster
⦁ Development Time Comparison
| Task | Without Definitions | With Definitions |
|---|---|---|
| Scaffold all 7 Zeebe workers | 4–6 hours (+ debugging wrong types) | 45 min (correct on first pass) |
| Wire IDP extraction output merging | 2–3 hours (AI generates code for managed connector) | 20 min (definition marks it as SaaS-managed) |
| Implement AI Agent response parsing | 3–4 hours (schema mismatch with BPMN) | 30 min (JSON schema in definition) |
| Set up message correlation | 1–2 hours (missing TTL, wrong correlation key) | 15 min (rules in definition) |
| Onboard second developer | 2–3 weeks reading code | 2–3 days reading definition file |
| Total for initial worker implementation | ~15–20 hours | ~3–4 hours |
The definition file for this project is approximately 200 lines of structured markdown. It took about 2 hours to author initially (mostly extracting what was already in the BPMN). It has paid for itself many times over in every subsequent development session.
⦁ How do you test AI-generated code in Camunda?
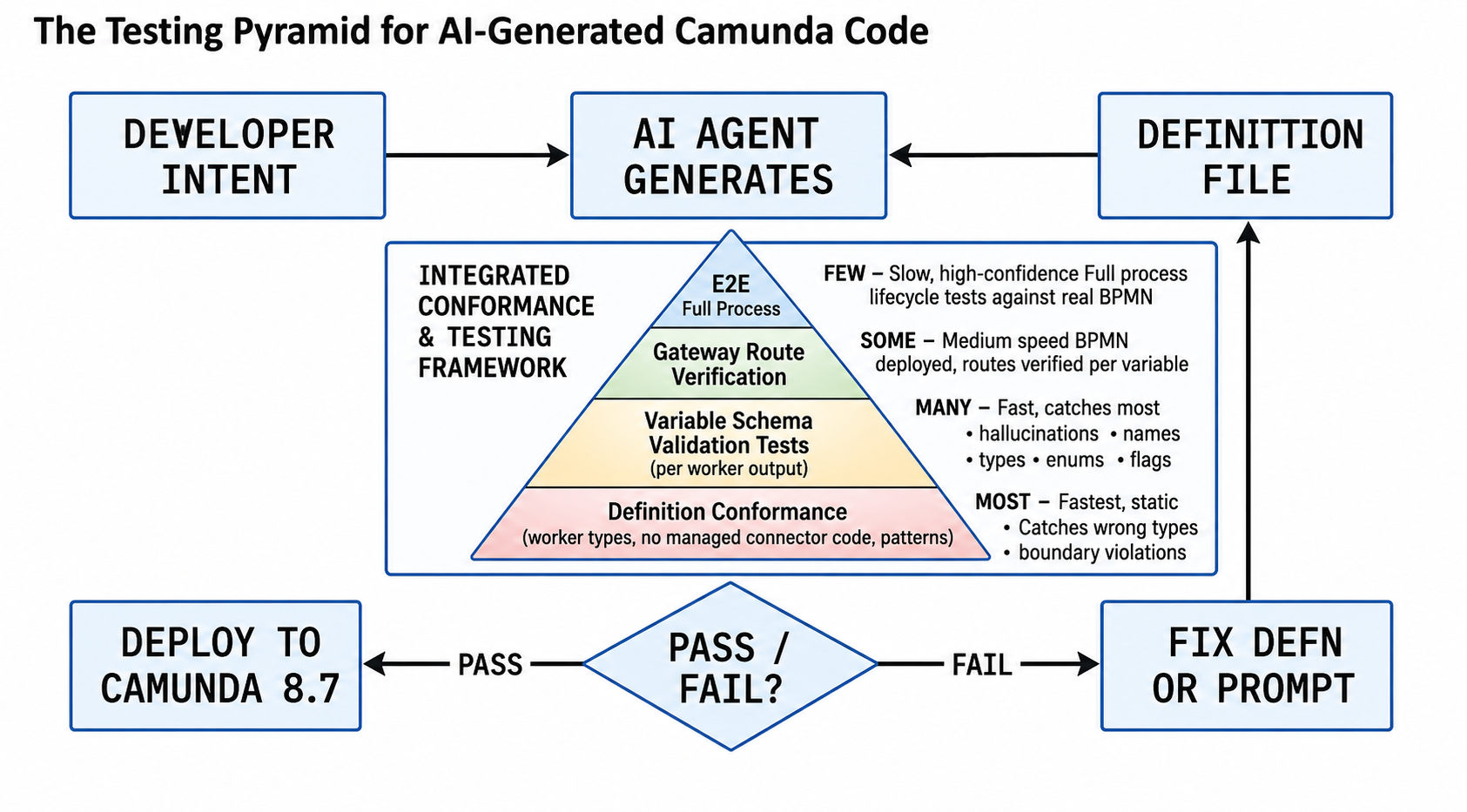
A definition file without tests is just a wish list. The real power of the approach comes when you can programmatically verify that AI-generated code conforms to the definitions. This is the testing strategy that closes the loop.
These tests run without starting Camunda. They parse the generated Java code and assert that it matches the definition file. Think of them as “contract tests between the AI and the BPMN.”
What these catches: AI agents generating custom REST clients for the IDP extraction connector, inventing new worker type strings, or creating duplicate HTTP call logic for things already handled by ‘io.camunda:http-json:1’.
Layer 2: Variable Schema Validation Tests
These tests verify that all worker’s output variables match the exact names, types, and valid values specified in the definition.
What these catches: The most common hallucination in AI-generated Camunda code — variable naming mismatches that silently break gateway conditions. A worker that outputs claimValid: true instead of claimValidationStatus: “SUCCESS” will compile, pass basic tests, but cause the exclusive gateway to take the wrong branch in production.
Layer 3: BPMN Gateway Route Verification (Process-Level Tests)
These tests use Camunda’s testing utilities to deploy the actual BPMN and verify that process instances route correctly through gateways when workers produce definition-compliant output.
What these catches: Integration failures that unit tests miss entirely. Even if every worker individually produces correct output, the BPMN’s gateway conditions are evaluated by the Zeebe engine using FEEL expressions. A mismatch between what the worker outputs and what the gateway expects only surfaces here.
Layer 4: Zeebe Message Contract Tests
These tests verify that message correlation — the communication mechanism between external systems and the Camunda process — adheres to the definition’s rules.
What these catches: Silent failures. A message without a TTL doesn’t throw an error — it simply arrives and expires before the receive task can correlate it. The process instance hangs indefinitely. This is the kind of bug that only tribal knowledge (or a definition file) prevents.
Layer 5: End-to-End Process Instance Tests
The final layer runs a complete process path through the real BPMN with mocked external services, verifying the entire claim lifecycle works end-to-end. You can build the End-to-End test suites also using Playwright which can achieve the complete flow of the process instance.
The Testing Pyramid for AI-Generated Camunda Code
 Why use Camunda 8.7 for AI-driven process automation?
Why use Camunda 8.7 for AI-driven process automation?
Camunda 8.7+ introduces capabilities that make definitions-driven vibe coding especially powerful:
- Agentic AI Connectors: The io.camunda.agenticai:aiagent:1 connector lets you embed AI agent tasks directly in BPMN. When your definition specifies the structured JSON response schema — fields like agentReply, conversation, fetchSSN, confidenceScore — the AI coding agent generates worker code that produces output in exactly the format the BPMN expects.
- IDP Connectors with Gemini 2.5. The IDP extraction connector (io.camunda:idp-extraction-connector-template:1) is SaaS-managed. Your definition should mark these as “no-code” zones while defining extraction prompt templates and output schemas (like jsonOutput taxonomy items) so AI agents generate the surrounding orchestration correctly.
- Structured Response Formats. Camunda 8.7’s AI connectors support JSON Schema-based structured outputs. Defining these schemas in your skill file means AI agents generate workers whose output matches exactly — including nested objects like agentJson, enum-constrained fields like conversation: “CONTINUE” | “END”, and nullable fields with proper defaults.
- Camunda Copilot. Released in 2024, it already generates BPMN from natural language. Pair it with definition files and you have a two-layer AI system: Copilot generates the process model; your definition file ensures the implementation code matches it.
The Industry Context: Why This Matters Now
The numbers from Camunda’s ecosystem tell the story of why definitions can’t wait:
- 87% of organizations have seen increased business growth from process automation (2025 State of Process Orchestration Report)
- 83% plan to increase automation investment by 10% or more
- Yet 72% say automation initiatives can’t keep pace with their rate of organizational change
- Organizations average 50 process endpoints across their business processes — up 19% over five years
- 78% say complex workflow patterns and long-running processes increase difficulty in end-to-end automation
The pressure is real: organizations are expected to deliver more automation, faster than ever. But the risk is equally real—AI-generated code accumulates technical debt at an accelerated pace.
Definitions act as the release valve. They allow teams to capture the speed and productivity gains of AI while preventing the uncontrolled buildup of technical debt.
The Practical Workflow: How It Works Day-to-Day
Step 1: Author the Definition File
This is typically a CLAUDE.md, AGENTS.md, CURSOR_RULES.md, or equivalent project-level instruction file. It’s written once and updated as the BPMN evolves. Think of it as a living architectural contract. Time investment: 2–4 hours for a complex process, mostly extracting information that already exists in your BPMN and tribal knowledge.
Step 2: Feed It as a rules to Your AI Agent
Whether you’re using Claude Code, Antigravity, Copilot, Cursor, Warp, Windsurf, or any AI coding assistant, the definition file becomes the agent’s primary context. It’s not a one-shot prompt — it’s a persistent skill that shapes every generation.
Step 3: Prompt with Intent, Not Implementation
Instead of writing:
“Create a Spring Boot service task handler for Zeebe that validates uploaded documents, checks file types, and sets ‘allDocumentsValid’ to true or false”
You write:
“Implement the validate-upload-documents worker”
The AI agent already knows the worker type, the input/output variables, the error handling pattern, and the architectural constraints. It generates production-ready code with the correct annotations, variable names, and patterns.
Step 4: Iterate Within the Sandbox
When you need to modify behavior — say, adding a new validation rule to the document checker — the AI agent generates changes that respect the existing variable schema and gateway conditions. It won’t accidentally rename allDocumentsValid to documentsAreValid and break the downstream BPMN routing.
Building Your Own Definition File: A Checklist
If you’re starting a Camunda 8.7 project and want to adopt this approach:
- Process layer — Process ID, platform version, execution environment (SaaS vs self-managed), cluster details.
- Task layer — Every service task type string, its purpose, expected input variables, and output variables with types and valid values.
- Connector layer — Which connectors are SaaS-managed (IDP, AI Agent, HTTP JSON), their template IDs, and what configuration they expect.
- Variable layer — Complete variable schema with names, types, enums, defaults, and which tasks produce/consume each variable.
- Integration layer — External systems (databases, Keycloak, OpenAI, GCP Vertex AI), connection patterns, and quirks (retry delays, TTLs, indexing lags).
- Entity layer — Key domain entity relationships that workers need for database operations.
- Anti-patterns — Explicit “don’t do this” rules. Don’t generate code for managed connectors. Don’t use Camunda 7 APIs. Don’t hardcode credentials.
The Bigger Picture
Vibe coding with definitions isn’t just a Camunda technique — it’s a response to a real industry problem. The data is clear:
- AI-assisted development delivers 3–5x speed gains on well-bounded tasks
- But 45% of AI-generated code contains security flaws that aren’t improving with newer models
- And incident rates increase 23.5% alongside productivity gains when AI code goes unguided
- Process orchestration with Camunda delivers 408% ROI — but only when the code actually matches the BPMN
The developers who thrive in 2026 won’t be the ones writing the most prompts. They’ll be the ones writing the best definitions — clear, precise, machine-readable architectural contracts that turn AI agents from unreliable interns into reliable collaborators.
Your BPMN is your specification. Your definition file is the bridge that lets AI agents understand and respect that specification.
Stop vibe coding in the dark. Define the vibe and let the agents execute with confidence.
Sources: Veracode 2025 GenAI Code Security Report | Forrester Total Economic Impact of Camunda | Camunda 2025 State of Process Orchestration Report | CodeRabbit AI vs Human Code Analysis (Dec 2025) | METR Developer Productivity RCT (July 2025) | Georgia Tech Vibe Security Radar | Cortex Engineering in the Age of AI 2026 Benchmark | Apiiro Fortune 50 Enterprise Research | Cloud Security Alliance AI Safety Initiative (April 2026) | Collins Dictionary Word of the Year 2025
